Předpokládejme, že máme k dispozici realizaci
![]() náhodného výběru
náhodného výběru
![]() z
z ![]() . Obor hodnot
. Obor hodnot ![]() náhodné veličiny
náhodné veličiny ![]() rozdělíme na
rozdělíme na ![]() disjunktních tříd
disjunktních tříd ![]() - a to
následovně:
- a to
následovně:
1. Je-li ![]() diskrétní náhodná veličina, volíme za třídy
diskrétní náhodná veličina, volíme za třídy ![]() jednotlivé body
oboru hodnot
jednotlivé body
oboru hodnot ![]() . Mluvíme o tzv. prostém třídění.
. Mluvíme o tzv. prostém třídění.
2. Je-li ![]() spojitá náhodná veličina, volíme za třídy
spojitá náhodná veličina, volíme za třídy ![]() intervaly.
Mluvíme o tzv. skupinovém třídění.
intervaly.
Mluvíme o tzv. skupinovém třídění.
Při třídění pak dodržujeme určitá pravidla. Např.
a) V případě skupinového třídění se doporučuje, aby intervaly ![]() měly
stejnou délku a aby hranice a středy tříd byly zaokrouhlená čísla.
měly
stejnou délku a aby hranice a středy tříd byly zaokrouhlená čísla.
b) Vyskytuje-li se v hraničních třídách velmi málo hodnot, je často vhodné spojit tyto třídy (nebo třídu) se sousední třídou v třídu jedinou.
c) Doporučuje se, aby počet ![]() výsledných tříd byl 5-20 podle rozsahu
výběru
výsledných tříd byl 5-20 podle rozsahu
výběru ![]() (pokud je to možné). Podle
Sturgesova pravidla by pro počet
(pokud je to možné). Podle
Sturgesova pravidla by pro počet ![]() tříd mělo platit
tříd mělo platit
Označme dále ![]() počet hodnot, které padly do třídy
počet hodnot, které padly do třídy
![]() . Číslo
. Číslo ![]() nazýváme
absolutní četnost třídy
nazýváme
absolutní četnost třídy
![]() .
Zřejmě
.
Zřejmě
Označme nyní ![]() počet prvků, resp. délku třídy
počet prvků, resp. délku třídy
![]() v případě prostého, resp. skupinového
třídění. Definujme reálnou funkci
v případě prostého, resp. skupinového
třídění. Definujme reálnou funkci ![]() předpisem
předpisem

V případě prostého třídění je
V případě skupinového třídění je součet obsahů obdélníků v histogramu (tj.
obsah obrazce ohraničeného osou ![]() a histogramem) roven jedné. Tedy
a histogramem) roven jedné. Tedy
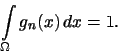
Častěji se používá histogram relativních
četností, resp. absolutních
četností, kdy se na osu ![]() nanesou třídy
nanesou třídy ![]() a nad každou třídou se
sestrojí "obdélník" o výšce rovné relativní, resp. absolutní
četnosti třídy
a nad každou třídou se
sestrojí "obdélník" o výšce rovné relativní, resp. absolutní
četnosti třídy
![]() . Horní obrys těchto obdélníků je pak histogram relativních, resp.
absolutních četností. Nevýhodou těchto histogramů je, že pozbývají vlastnosti
rozdělovacích funkcí. Tak např. v případě skupinového třídění nemusí být
obsah plochy mezi histogramem relativních četností a osou
. Horní obrys těchto obdélníků je pak histogram relativních, resp.
absolutních četností. Nevýhodou těchto histogramů je, že pozbývají vlastnosti
rozdělovacích funkcí. Tak např. v případě skupinového třídění nemusí být
obsah plochy mezi histogramem relativních četností a osou ![]() roven jedné.
Chceme-li mít orientační představu o tvaru teoretické rozdělovací funkce,
stačí ale tyto histogramy sestrojit.
roven jedné.
Chceme-li mít orientační představu o tvaru teoretické rozdělovací funkce,
stačí ale tyto histogramy sestrojit.
Uvědomme si, že jsme pracovali s
realizací náhodného výběru z ![]() a tudíž
a tudíž ![]() , resp.
, resp. ![]() byly vlastně
realizace náhodných veličin
byly vlastně
realizace náhodných veličin ![]() , resp.
, resp. ![]() a pro každou realizaci náhodného
výběru z
a pro každou realizaci náhodného
výběru z ![]() dostaneme
obecně jiné realizace
dostaneme
obecně jiné realizace ![]() a tudíž i jiné histogramy. (Nehledě na to,
ze samotné třídění je subjektivní a tudíž pro jedinou realizaci můžeme
dostat
různé histogramy.)
a tudíž i jiné histogramy. (Nehledě na to,
ze samotné třídění je subjektivní a tudíž pro jedinou realizaci můžeme
dostat
různé histogramy.)